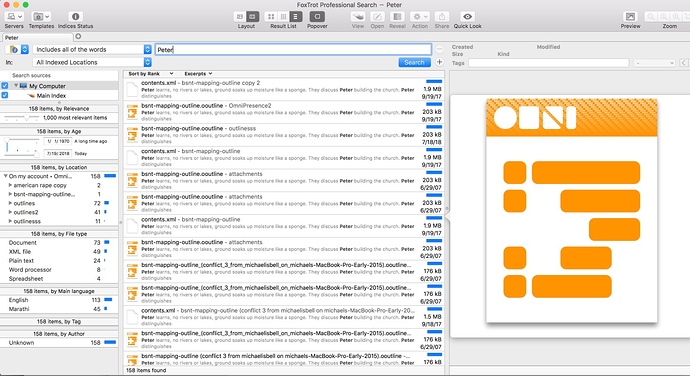
I came up with a way to do it, with a few issues I’ll discuss at bottom. This works, and I’m using it now.
how to grep your omnioutliner ooutline files
#first move .ooutline files to another directory
mkdir -p outlines2
for file in *.ooutline; do
echo cp ‘"$file"’ ./outlines2/
done
#then in the remove the .ooutline extension from the files
cd ./outlines2
for file in *.ooutline; do
echo mv ‘"$file"’ $(echo $(echo ‘"$file" | cut -f 1 -d ‘.’ )’) ;
done
#then rename the files to .zip
for file in * ; do
echo mv ‘"$file"’ $(echo $(echo ‘"$file".zip )’) ;
done
#then unzip the outline file contents into separate folders
for file in *.zip ; do
echo unzip ‘"$file"’ -d $(echo $(echo ‘"$file" | cut -f 1 -d ‘.’ )’) ;
done
#now you can grep your outline files for content:
find . -iname *.xml -print0 | xargs -0 grep -Eo ‘.{0,40}Peter.{0,40}’ *.xml
Issues:
-
I have to run each for loop as a script and then pipe the generated mv etc commands to an output file, which I then chmod a+x and run as a batch file. Why? Because the commands in the loop, while generate fine with the echo, don’t run; and when I remove the echo, I get syntax errors.
-
This is my first ever real bash script, so, you know, it is what it is. I’ll get better.
-
the escaped single quotes make it work with filenames with spaces, which I have many of.
-
the rename to zip loop also renames my sh scripts grrr oh well.
that said, this does exactly what I want it to do. I get output like this from the grep: (excuse content, it’s for a novel)