Hello, everyone! A while ago, Ken mentioned that we are in the process of adding client-side encryption support to our products. There are several places we think encryption is worthwhile, and they each require their own approach. Right now, I want to talk about what we’re working on for OmniFocus Sync encryption.
We’ve always encrypted the communications between OmniFocus and the server, of course. But we’d like to do better. The only things which should ever have access to your OmniFocus tasks are the devices you own and control: your phone, your Mac, your tablet.
What does this mean for you? There are positive and negative aspects. The positive aspect is that you can be more sure of the privacy of your OmniFocus tasks, whether they’re stored on our server or a third-party server. You should be able to put sensitive data in OmniFocus without worrying about auditing our datacenter. The other side of the coin, though, is that we won’t be able to look at your data even if you ask us to- unless you also give us the passphrase. If you lose your passphrase and all of your devices, there will be nothing we can do; we can’t recover or reset a passphrase. We think that, for most people, this is a good tradeoff.
What follows is very technical. I’m going to describe in more detail what we’re trying to achieve and what cryptographic techniques we’re using. We’d love to hear feedback on this: if you have a need that this doesn’t quite cover, or if you think we’ve missed a risk or an opportunity, please let us know. We are also having this reviewed by experts. But the more eyes, the better!
It’s likely that there will be changes to this before it becomes final. But we will document the final version. Our goal is not to hold your data hostage.
Goals and Threat Model
“Before I built a wall I’d ask to know / What I was walling in or walling out” - Robert Frost
Our main goal is to secure your data against a passive attacker: someone who can read the files on the server, intercept them on the network, look at old backup tapes, etc., but who cannot modify your files on the server. This describes a lot of real-world compromises. The passive attacker should be able to learn very little about your use of OmniFocus. They will, by definition, be able to tell when you’re making changes and syncing them, and they can tell if you’ve added an especially large attachment, for example, because of the increase in traffic. But they should not be able to read the contents of any of your tasks.
We can’t provide complete protection against an active attacker, who can modify files on the server. But we will limit their options as much as we can.
An attacker might learn an old passphrase of yours, or might learn a current passphrase but only have access to an old copy of your database. In these cases, we want to ensure they still can’t read your information. Additionally, if someone has access (to both your database and passphrase), and you change the passphrase, they should not be able to read tasks you add after changing your password.
There are a lot of scenarios we’re not trying to deal with, at least not with this feature. For example, if someone compromises your phone or your Mac, there’s very little we can do. However, Apple provides many protections in the form of Data Protection, FileVault, Gatekeeper, and so on. OmniFocus Sync encryption is meant to fit into the larger system of security technologies, not to re-invent wheels you already have.
We have some other goals, as well. We’re intentionally preferring “boring” algorithms, which are widely used, and which are available in Apple’s system frameworks (the less low-level crypto we have to ship, the better for everyone).
Overall Design
It’s simple: You enter a passphrase, we encrypt your data with that passphrase.
Okay, it’s not that simple. An OmniFocus sync database is a directory full of files which are read and written asynchronously by multiple clients that don’t have other ways to communicate.
An encrypted database has one extra file, the “encryption metadata” or key management file. Your passphrase decrypts this file, which contains one or more file-encryption subkeys, each with an identifying key index.
Individual files start with the key index of one of the keys in the key management/metadata file, and then are encrypted using that key.
When the user changes their passphrase, therefore, we don’t need to re-encrypt every file immediately. We can simply re-encrypt the metadata blob with the new passphrase. At the same time, we add a new key to it, and mark the new key as “active”, and the old key as “retired”. Any new files uploaded by OmniFocus clients after this point use the new subkey, and old data is eventually re-encrypted or deleted, at which time the “retired” subkey is deleted.
Concrete details
TL;DR: PBKDF2-SHA256, AESWRAP, AES128-CTR, HMAC-SHA256.
The metadata / key management file is a plist containing PBKDF2 parameters, and an encrypted blob. Your passphrase is fed to PBKDF2, and the result is used as an AES-256 key to unwrap (decrypt) the encrypted blob using AESWRAP. The blob contains a collection of file subkeys, each identified by a key index (a small integer). Most of the time, there will be only one key in the blob.
Individual files contain (after a magic number) the index of the key with which they are encrypted. Using this key index, OmniFocus retrieves an AES key and a HMAC key from the key management blob, and encrypts the file using AES in CTR mode and HMAC-SHA256 as an integrity check.
Most files are quite short (maybe 1kB), but some are large (gigabytes). CTR mode is used for its random-read-access capability: sometimes, we may want to be able to read a sub-range of the file without decrypting the whole thing. For this reason, the encrypted data is broken into segments of (up to) 65536 bytes. Each segment has its own CTR IV and HMAC. The file as a whole has an HMAC which is simply the HMAC of every segment’s HMAC- like a 1-level Merkle tree.
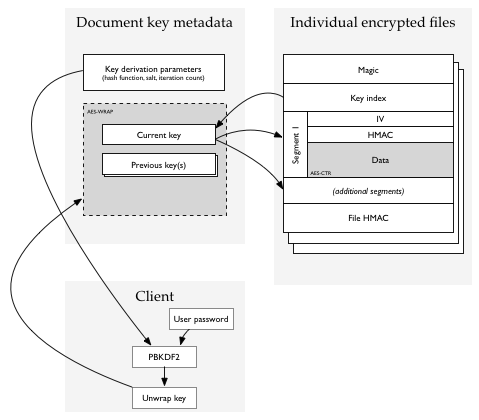
A file consists of:
- Fixed-length header containing magic number and key index
- File magic (a fixed string to identify encrypted files)
- Key information length (2 bytes, size of next section not including padding)
- File key information
- Key index (2 bytes). Selects a document key for unwrapping the file key.
- Any encrypted information needed by the key. Currently, this is empty.
- Padding to a 16-byte boundary. Must be zero; must be checked by reader.
- Variable-length array of encrypted segments
- Segment IV (12 bytes = block size minus the 32-bit AES-CTR counter)
- Segment MAC (20 bytes): the truncated HMAC-SHA256 of ( IV || segment number || encrypted data ) where the segment number is a 32-bit number.
- Segment data (SEGMENTED_PAGE_SIZE = 64k bytes, except possibly for the last segment): encrypted with initial IV of ( IV || zeroes ) as is normal for CTR mode.
- Trailer
- File HMAC: (SEGMENTED_FILE_MAC_LEN = 32 bytes) computed over a version identifier (currently, the single byte 0x01) and the segment MACs concatenated in order.
Why not… ?
Why not GCM? GCM or GHASH isn’t available from the system libraries, and although HMAC-SHA256 is slower, it’s still fast enough. GHASH is easy for us to implement in our code, but probably hard for us to implement securely.
Why not ChaCha+Poly1305, or something like that? Technically, we could certainly use a different AEAD algorithm. We’re trying to stick to boring, tried-and-true algorithms wherever possible, and unless we have a good reason we’re also trying to stick to algorithms which are available in CommonCrypto. Right now, that means AES and SHA.
Weaknesses
Our forward and reverse secrecy is not perfect: key rollover is not instant, since it involves re-encrypting and re-uploading everything. We wait until the next time we have to rewrite the server database (a “compaction”) to eliminate the use of the old subkeys.
An active attacker (or server administrator) can roll back the database to a previous state or delete files. However, OmniFocus’s sync algorithm will typically silently repair this kind of damage.
Because OmniFocus compresses its files, we’re vulnerable to information leakage similar to the CRIME attack: someone with the ability to add tasks to your database and to observe your sync traffic can, potentially, probe for the existence of particular text in your database. It would be hard to do this without the user noticing, though.
An active attacker can rename files without detection. We’ll probably add protection against this before finalizing the format.
Possibilities for Future Development
There are several features that are desirable but which we aren’t working on for this release. We’re trying to leave ourselves the flexibility to add them later:
Password-less encryption
Passwords are what people are used to, but they have a lot of problems, and can be inconvenient to use securely. Perhaps in the future we can eliminate them in favor of some other form of key agreement or secret-sharing among your devices.
Key Escrow
Right now, if you lose your encryption passphrase and all of your devices, there’s no way to recover your data. From a security perspective, that’s great. But it’s often nice to be able to leave a “spare key” somewhere: perhaps with us, perhaps with your company’s IT people, perhaps with your spouse.
Write-only Encryption
Tools like Quick Entry and Mail Drop would ideally be able to write a file that OmniFocus can read, but no one else (including Mail Drop) can. The encryption metadata file could contain an asymmetric keypair for this purpose.
