Looks good :-)
If the translation directions multiply, it can be good to use JSON / JS Objects as a hub for nested texts (outlines), something like this:
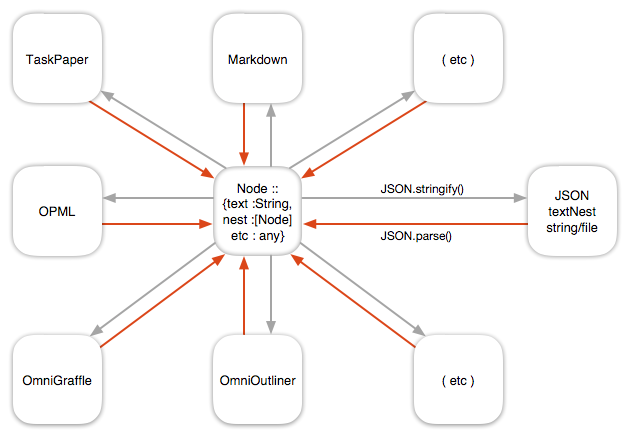
Rough two stage example below:
- OmniOutliner to
[Node {text:String, nest:[Node], ...}] -
[Node {text:String, nest:[Node], ...}]to Markdown, (with same options as iThoughts exporter)
var strClip = (() => {
'use strict';
// OmniOutliner to TEXT-NEST, then TEXT-NEST to MARKDOWN
// example of format translation through a textNest hasSubTopics
// Rough draft ver 0.05
// 0.05 -- Moved extra linefeed from after hash header to before
// 0.04 -- Simplified ooRowsJSO
// 0.03 -- Slightly faster version of cellTextMD – fewer AE events
// Copyright(c) 2017 Rob Trew
//
// Permission is hereby granted, free of charge, to any person obtaining a
// copy of this software and associated documentation files(the "Software"),
// to deal in the Software without restriction, including without limitation the rights
// to use, copy, modify, merge, publish, distribute, sublicense, and / or sell
// copies of the Software, and to permit persons to whom the Software is
// furnished to do so, subject to the following conditions:
//
// The above copyright notice and this permission notice shall be included in all
// copies or substantial portions of the Software.
//
// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.IN NO EVENT SHALL THE
// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
// SOFTWARE.
// GENERIC ----------------------------------------------------------------
// any :: (a -> Bool) -> [a] -> Bool
const any = (f, xs) => xs.some(f);
// concat :: [[a]] -> [a] | [String] -> String
const concat = xs =>
xs.length > 0 ? (() => {
const unit = typeof xs[0] === 'string' ? '' : [];
return unit.concat.apply(unit, xs);
})() : [];
// curry :: Function -> Function
const curry = (f, ...args) => {
const go = xs => xs.length >= f.length ? (f.apply(null, xs)) :
function () {
return go(xs.concat(Array.from(arguments)));
};
return go([].slice.call(args, 1));
};
// flip :: (a -> b -> c) -> b -> a -> c
const flip = f => (a, b) => f.apply(null, [b, a]);
// isInfixOf :: Eq a => [a] -> [a] -> Bool
const isInfixOf = (needle, haystack) =>
haystack.includes(needle);
// log :: a -> IO ()
const log = (...args) =>
console.log(
args
.map(show)
.join(' -> ')
);
// min :: Ord a => a -> a -> a
const min = (a, b) => b < a ? b : a;
// replicate :: Int -> a -> [a]
const replicate = (n, a) => {
let v = [a],
o = [];
if (n < 1) return o;
while (n > 1) {
if (n & 1) o = o.concat(v);
n >>= 1;
v = v.concat(v);
}
return o.concat(v);
};
// replicateS :: Int -> String -> String
const replicateS = (n, s) => concat(replicate(n, s));
// show :: a -> String
const show = x => JSON.stringify(x, null, 2);
// zipWith :: (a -> b -> c) -> [a] -> [b] -> [c]
const zipWith = (f, xs, ys) =>
Array.from({
length: min(xs.length, ys.length)
}, (_, i) => f(xs[i], ys[i]));
// JSO TEXT-NEST TO MARKDOWN ----------------------------------------------
// jsoMarkdown :: Dictionary -> [Node] -> String
const jsoMarkdown = (dctOptions, xs) => {
const
indent = dctOptions.indent || '\t',
headerLevels = dctOptions.headerLevels || 3,
listMarker = dctOptions.listMarker || '-',
notesIndented = dctOptions.notesIndented || true;
const
jsoNodeMD = curry((intLevel, strIndent, node) => {
const
blnHash = intLevel <= headerLevels,
index = node.number,
strNum = ((blnHash || (index === undefined)) ? (
''
) : index + '.'),
strPrefix = (blnHash ? (
replicateS(intLevel, '#')
) : strNum || listMarker) + ' ',
noteIndent = notesIndented ? strIndent + indent : strIndent,
nextIndent = blnHash ? '' : indent + strIndent,
note = node.note,
strNotes = (note !== '') ? (
note.split('\n')
.map(x => noteIndent + x)
.join('\n') + '\n\n'
) : '',
nest = node.nest;
return (blnHash ? '\n' : '') +
strIndent + strPrefix + node.text + '\n' +
strNotes + (nest.length > 0 ? (
nest.map(jsoNodeMD(intLevel + 1, nextIndent))
.join('') + '\n'
) : '');
});
return xs.reduce((a, x) => a + jsoNodeMD(1, '', x) + '\n', '');
};
// OMNI-OUTLINER TO JSO / JSON --------------------------------------------
// Either with or without (see blnMD) MarkDown emphases for Bold/Italic
// ooRowsJSO :: Bool -> OO.Document -> [Node {text: String, nest: [Node]]}
const ooDocJSO = (blnMD, doc) => [{
text: '[' + doc.name() + '](file:://' + Path(doc.file())
.toString() + ')',
nest: ooRowsJSO(blnMD, doc.children)
}];
// ooRowsJSO :: Bool -> OO.Rows -> Node {text: String, nest: [Node]}
const ooRowsJSO = (blnMD, rows) =>
rows()
.map((r, i) => ({
text: blnMD ? cellTextMD(r.topicCell) : r.topic(),
number: r.style.attributes
.byName('heading-type(com.omnigroup.OmniOutliner)')
.value() !== 'None' ? i + 1 : undefined,
note: blnMD ? cellTextMD(r.noteCell) : r.note(),
nest: r.hasSubTopics ? ooRowsJSO(blnMD, r.children) : []
}));
// contains :: String -> String -> Bool
const contains = curry(flip(isInfixOf));
// cellTextMD :: OO.Cell -> String
const cellTextMD = cell => {
const as = cell.richText.attributeRuns;
return zipWith((txt, fnt) => {
const
bld = any(contains(fnt), ['Bold', 'Black']) ? (
'**'
) : '',
ital = isInfixOf('Italic', fnt) ? '*' : '';
return bld + ital + txt + ital + bld;
}, as.text(), as.font())
.join('');
};
// TEST -------------------------------------------------------------------
const ds = Application('OmniOutliner')
.documents,
d = ds.length > 0 ? ds.at(0) : undefined;
// Edit optional values for indent, headerLevels, notesIndented, listMarker
return d ? jsoMarkdown({
indent: replicateS(4, ' '), // or '\t'
headerLevels: 3,
notesIndented: true,
listMarker: '-' // or '*' or '+'
}, ooDocJSO(true, d)[0].nest) : '';
})();
var a = Application.currentApplication(),
sa = (a.includeStandardAdditions = true, a);
sa.setTheClipboardTo(strClip);
strClip
