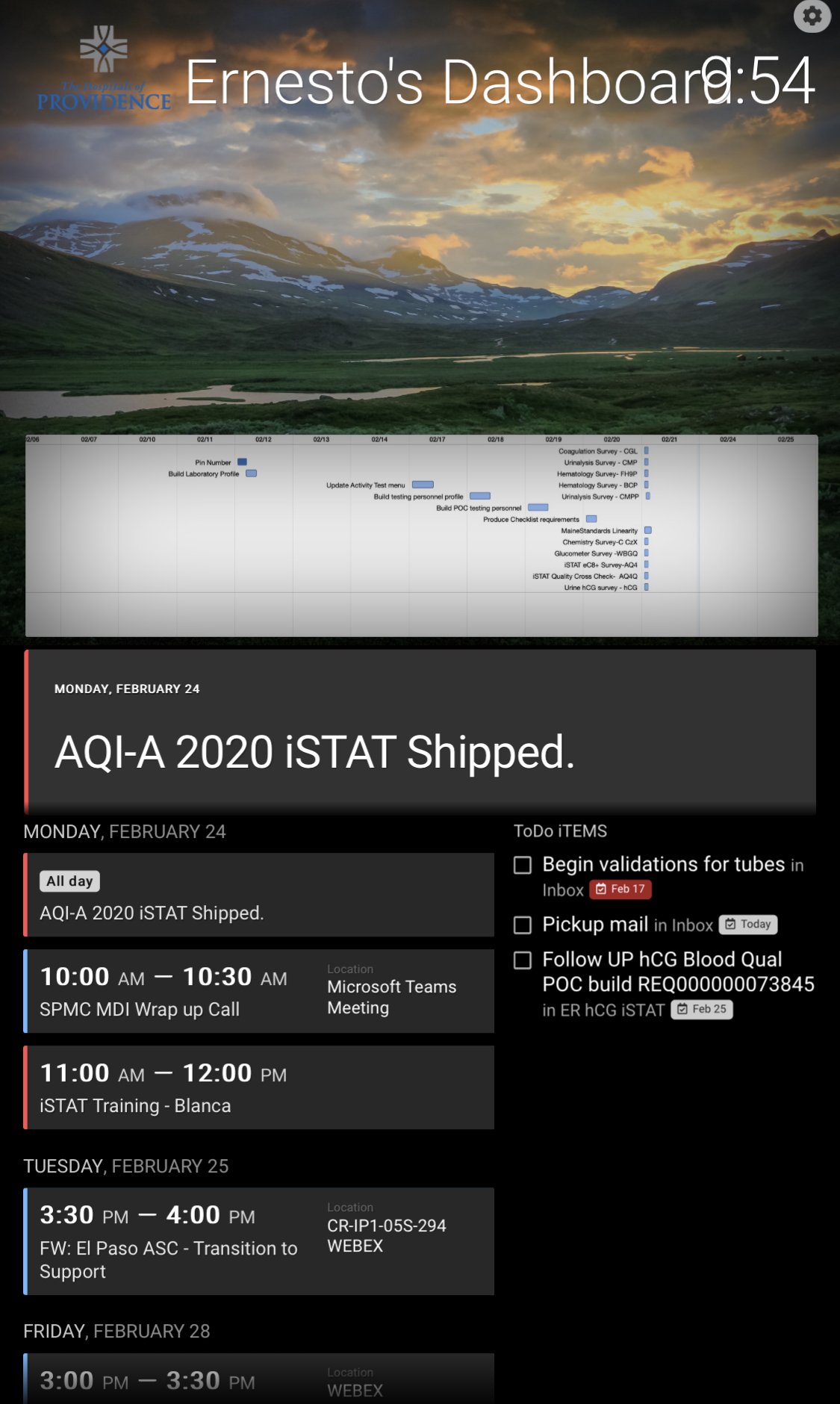
I’m using OmniFocus as a core piece of my family organizational dashboard. It’s helping keep my wife and I in sync, helping the kids track their chores, etc.
Everyone also has an ‘urgent’ context in OmniFocus, and I have a script that scrapes the OmniFocus web interface every day and sends an SMS to anyone that has urgent tasks due that day. It works, but it’s janky. I would love to API into the OmniFocus web database rather than scraping the web GUI. The scraping is particularly cumbersome because I need to emulate a full browser because the UI is javascript driven, rather than just parsing HTML responses.
I had been using RubyFocus (https://github.com/jyruzicka/rubyfocus), which directly accesses the database. However, it only works locally, as the implementation to decrypt the data over web-dav hasn’t been written (and is non-trivial).
I’m currently using some custom ruby code to submit the login at web.omnifocus.com and then hijack the websocket connection between the browser and the server. It is very rough right now. I’m not sure what the DAKboard architecture but I’ll share what I have once I anonymize it and clean it up (right now all of my credentials are hard-coded).
OmniFocus doesn’t really have a “database” in the usual sense, or any kind of smart service to manage it (kind of - see later…).
Each client stores updates since the last sync in zip files (encrypted) and pushes those to a file server where all your other clients (including the web client) can see them. The web client is in fact a headless instance of something derived from the desktop version of OmniFocus and works the same way.
Periodically one of the clients will determine that all the other clients have seen certain zip files and consolidate the “database” and all incremental transactions into one zip file. You can look at how many zip files you have in sync settings (at least on iOS).
The advantage of this is that you can use your own dumb WebDAV server to host your own sync data.
The downside is that there’s no REST API or service to interrogate, you have to download, decrypt and unpack the zip files.
It’s not entirely true that there’s no service associated with OmniFocus:
There is a mail service that receives inbound messages and puts them into your inbox - probably by adding a zip file!
There is some sort of new upload monitoring that sees sync file changes and sends a push notification to trigger all your clients to download any changes.
Linked from that post is also a Python script which will decrypt your OmniFocus database, giving you a stack of plaintext zip files. (It would probably be straightforward to transliterate the script into Ruby; there’s nothing fancy going on in there.) If you want to extract data in bulk, that’s probably the best way to do it. However, they’re not a format that’s very convenient for “querying” the data; they’re mostly deltas from a previous state.
If your situation allows, you might try using the upcoming automation support in OmniFocus (see our roadmap and this comment — it’s not fully released yet, but it’s available for testing).
Also, I feel obliged to mention that that websocket protocol is very much not a stable interface or supported API. It’s pretty tightly coupled to the javascript that runs on the browser and could change at any time.
Wow , all this just went over my head, now I got some more learning to comprehend, but from what I gathered it is doable at least in the near future with some learning.
Sorry, there isn’t an ETA. (I don’t actually work on that, so I wouldn’t know anyway.)
If you haven’t already, please send in a feature request for the API describing your use case (what you’re trying to achieve in general, and what API calls/affordances you think would get you there). It’s very helpful for us to have that kind of information when we’re planning a new feature!