I started a plugin to work with books. It will search Goodreads for the task name, prompt the user to review the matches, and then update the task with book metadata. Additional sources such as your local library can be checked and the task annotated with a tag or keyword in the name if the library has it available.
Enter your books:
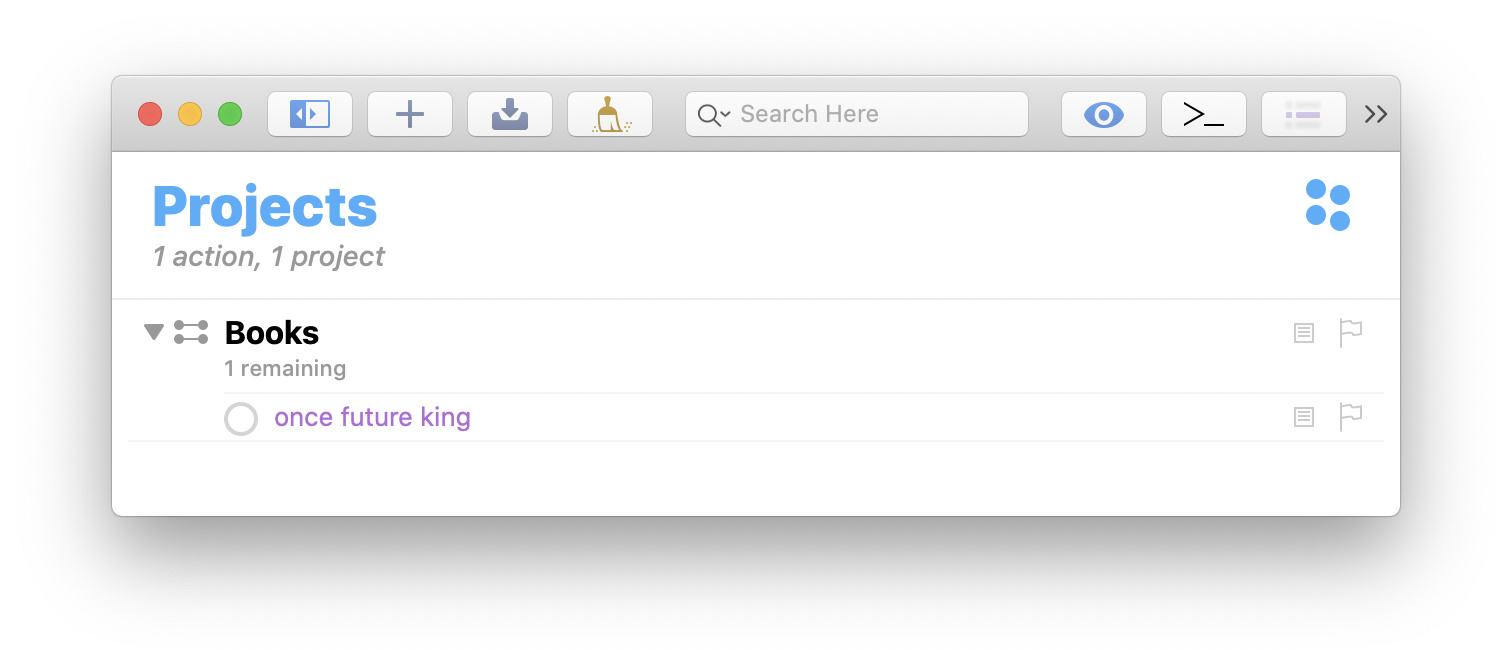
Select the match:
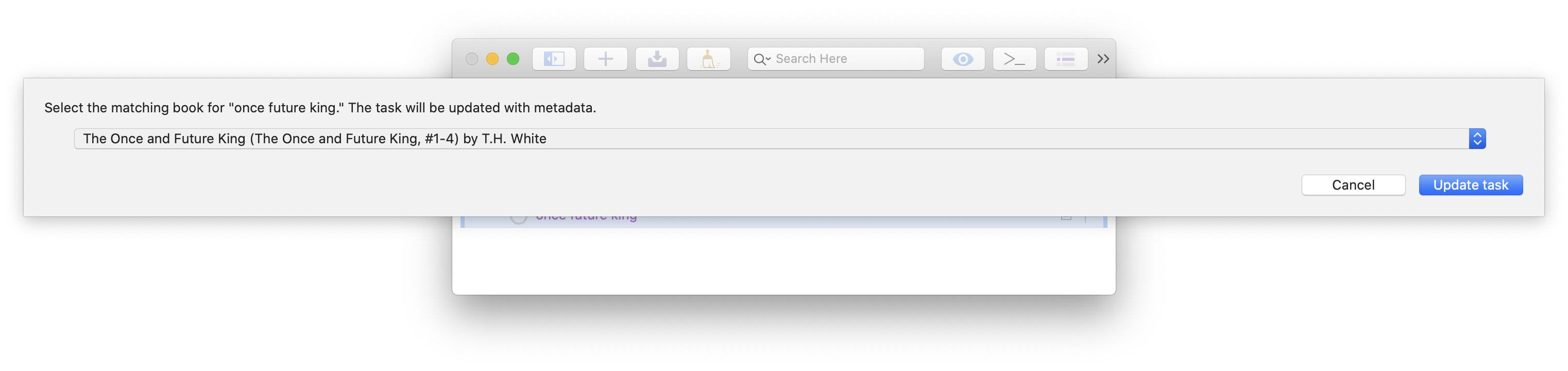
And the task is updated, including with an indication it is available at the library:
Books.omnifocusjs.zip (27.7 KB)
Some thoughts on the API after going through this exercise:
Calling web services limitations
The automation API is understandably focused on working with the database. I found the API to be quite limited for interacting with other services and this is an area to consider for improvement. The documentation (https://omni-automation.com/shared/url.html) suggests that calling out to web services is within the intended scope of the API, however the available tools (URL.fetch() and JSON.parse()) are extremely limited. Some features that should be supported at the request layer:
- URL.fetch() calls the success callback for HTTP errors such as 404 not found or 401 not authorized. The HTTP code is not available on the result. (URL.fetch() fails to fail)
- HTTP requests other than GET (URL fetch/post?)
- Setting HTTP headers for e.g. authentication
- Reading HTTP headers returned by the server for e.g. authentication cookies or mime types
- Are there sufficient hooks to implement an OAuth flow?
Since we don’t have access to a low level networking socket, we can’t work around the limitations.
XML limitations
The other major limitation for web services I see is the absence of XML parsing. The example at https://omni-automation.com/shared/url.html demonstrates parsing XML with simple .indexOf() calls. This is a bad idea as XML if fiendishly difficult to parse correctly. There are many ways the document could change and be nominally identical per the XML spec but cause the demonstrated parser to fail (CDATA wrapping is the obvious example).
I have come to understand that JSON.parse() is part of ECMA v5 whereas XmlHttpRequest() is part of the browser web API which is why the former is included but the later is not. There are pure JavaScript XML parsers available so XML parsing can at least be added by users. However, it would be challenging for less experienced users.
I understand that an XML library might a considerable work to add to the API. As an intermediate step, I think a great addition to the plugin collection (https://omni-automation.com/omnifocus/actions.html) would be a plugin library with an XML parser. This would provide a great example of the utility of libraries and give new users something easy to use rather than string searching.
