Of course, I’d still like to see OO export markdown without such help.
2 Likes
I’m sure Markdown support will appear at some point, when I’m working on documents I use OmniOutliner. But when I’m exchanging files with colleagues or keeping them for long term Archive I use Markdown.
Import and Export into OmniOutliner would be top of my list, followed by Markdown support within OmniOutlier a secondary consideration.
I need this feature NOW.
I’ve been creating weekly reports in OmniOutliner… but I have no way to copy and paste the report into an email.,. at least none that i’ve found.
I mean, sure, I can get a simple “text” format, but then I have to go and painfully reformat the darn thing… I’m going to have to write a python script to do this form me!!
Is there any sort of “plugin” capability for OO that I could use to add a “Copy as Formatted…”?
@kutenai Could you explain what reformatting you need to do, please? My guess would be removing the handles and/or checkboxes. If you don’t want any, you can control this by clearing the fields in the Text or RTF Export tabs of the Preferences. You can even change indentation values if you want something different.
The output indentation and formatting does not translate well to my mail client – MailMate – which accepts a nice markdown format. I just want the Header rows to have a ‘#’ as prefix, and then indent the child rows.
You pointed out the configuration options, and that will help actually. I can make the ‘header rows’ have a # in front of them. Would be nice to have some additional controls, but this help.
As a side-note, I used bbedit and a custom text filter to re-format to clean Markdown.
What would be great would be controlling the handles on export - maybe simply having hashtags instead of handles or even determining the number of hashtags (ie markdown title hierarchy).
Only possible problem then would be differentiating between ‘text’ and ‘title’ maybe this is done somehow via checkboxes ?
Clumsy workaround would be putting all ‘text’ into notes…
I’ve been using a tool called Ulysses. It’s really nice, but not a replacement for Omnioutliner. Still, it has some killer features.
- It syncs seamlessly with iCloud, including other computer and mobile… super nice!
- You can highlight a section of a document, and “copy as…” HTML, Markdown, Plain Text, or Rich Text.
That last feature is worth it’s weight in gold. I’d pay for an upgrade to OO right now if it has such a feature. Without the slightest hint of hesitation… OO6…
If any of you folks have bbedit, I have a text filter I use to convert the ‘cut-paste’ text from OO to markdown. It’s quite simple. You will need to adjust that first #! line.
The script takes tab indented stuff, and converts it to indented and *'ed markdown. It works, and could certainly be updated…
#!/usr/bin/env -S ${HOME}/bin/.venv3/bin/python
import fileinput
import re
import json
if __name__ == "__main__":
for a_line in fileinput.input():
line = a_line.rstrip('\s+\n')
m = re.match(r"^(\t*)[ ]*-\s+(.*)$", line)
if m:
tabs = m.group(1)
txt = m.group(2)
tabcount = len(tabs)
if tabcount == 0:
print("# {}\n".format(txt))
else:
print("{}* {}\n".format(" "*(tabcount-1), txt))
else:
print("Raw:{}".format(line))
1 Like
I keep hoping OO will pick-up importing MD outlines. This past week I had a large outline in MD using * and tabs for nesting. I used to have a workflow that worked passably, but I could not figure it out. I thought it was bringing MD into iThoughts or MindNode and exporting as OPML and pulling that into OO.
I know I have turned the * and tab into headers and had that work through a couple different workflows, but it doesn’t copy into Pages, Google Docs, nor Word well when I go that route.
I’m often starting an outline from a rough note (nearly all my notes start as markdown). Sometimes after a short while I will outline my notes in a mind map app, or OmniOutliner than round trip them using OPML from the other.
I like all the exporting MD from OO that I’m seeing shared out, now wondering about the other direction.
2 Likes
I’ll be honest, the developer replies in this forum have been really discouraging. There seem to be a lot of customers basically saying, “this is an important feature and would make my experience of this product better”. As far as I can see, the response has been to basically skirt those concerns and blame the fact that no single set of preferences exist for how they would be implemented.
I basically love the look and feel of your product. A direct export to markdown would make it much more useful for me, because I want to be able to get my rough outline (written in OO) into Ulysses and then fill it out there, with minimal rigmarole in export. The richtext and Docx exports are actually extremely useless to me, and the plaintext with tab indentation even more so. It seems like including a markdown export feature would be pretty simple, in the grand scheme of things—why not just believe your customers when they say this would be a desirable feature? The fact that people are resorting to pairing Hazel with Pandoc should tell you something about how much a simple export feature would help.
1 Like
Just floating this as an idea:
Regarding markdown as simply an export format, one solution could be to provide a user mapping between OmniOutliner styles and markdown prefixes.
So I could define some OO styles as:
- “Heading1” => markdown prefix "# "
- “Heading2” => markdown prefix "### "
- “ListItemLevel1” => markdown prefix "- "
- “ListItemLevel2” => markdown prefix " - "
- “QuotedLine” => markdown prefix " "
- etc. etc.
OmniOutliner would then just output the content flat and add the prefixes to the lines where specified by the style of the line itself.
Right. One of the issues with Markdown export from iThoughts is it has only limited customisation. In my case it doesn’t do what I want.
I would like, for example, to say that anything beyond 2nd level is progressively nested bullet list items.
@MartinPacker : If I understand you correctly, iThoughts provides what you want. See screenshot below where you can pick how indents are handled, how many header levels are used, and list markers. I can easily create a list where 3rd level and beyond are progressively nested bullet list items.
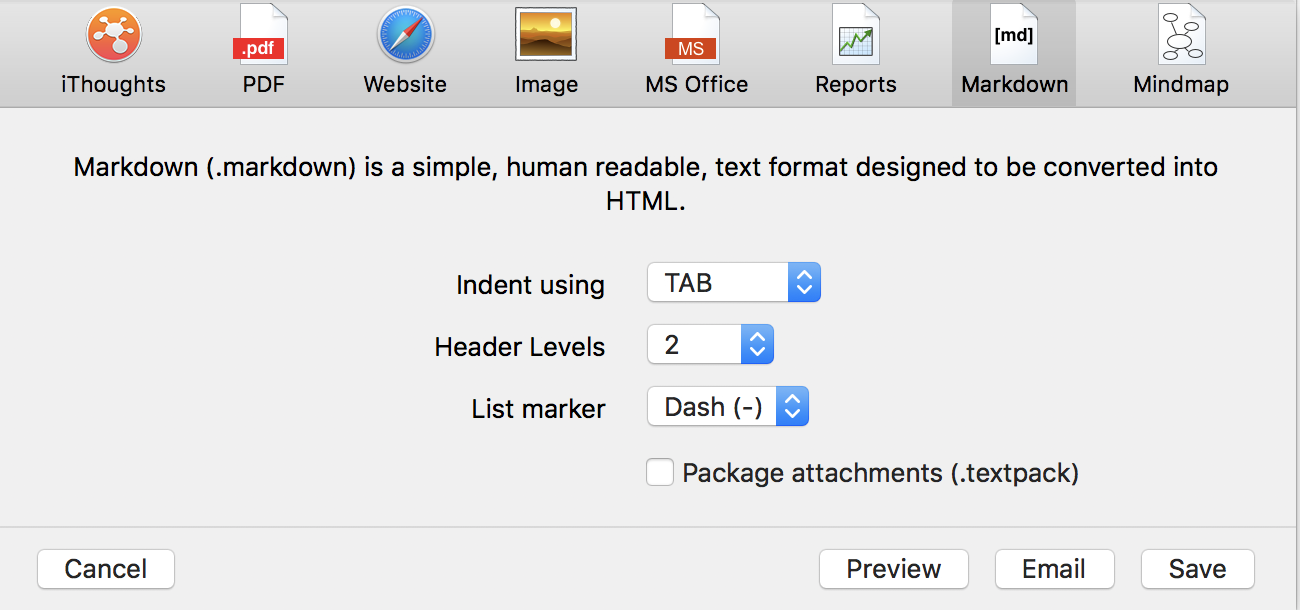
Right. I think it might well be “user error” in that my mind maps aren’t wonderfully congruent with this. (It’s the same issue with “direct to pptx” in iThoughts.)
In my case I probably want to conflate levels 3 and 4 into being ### - but that’s because of the way the mind maps tend to turn out.
The actual point I was making was that this “any further and you’re into bulleted lists” approach in iThoughts might be better than specifying each level separately - as the OP was mooting.
But also iThoughts’ model isn’t bad but might need to go further, whether adopted by OmniOutliner or not.
Ah, I understand. Yes, I like that approach by iThoughts. OmniOutliner could do well to adopt a similar approach.
I’m not sure how iThoughts’ model could go further: but any improvements would be welcome. Going from outline/mindmap to text is an important step. Having a clear and effective way to expert/transfer from one format to the other is always needed.
I was just checking MindNode: it gives you no choice at all. Headers for levels 1 through 3, then bullet lists. But you can’t change when the “switch” occurs.
1 Like
(Possibly) off topic for this forum but I worked on my mind map with a colleague and intend to export it to Markdown where we can edit it some more. Then put it through my md2pptx converter to make Powerpoint.
She’s new to Markdown so trying to make this as easy for the both of us as possible.
It might be more visibly compact to use OmniOutliner instead - and that COULD be made, with styling, to look more like the set of slides we’ll produce.
I suppose the answer is a tactical piece of Javascript.
Here’s my $.02 worth regarding Markdown support, for what it’s worth.
I love working with Markdown, as it is certainly a powerful-but-simple “lingua franca” for passing somewhat-structured, lightly-formatted data amongst various software packages and platforms.
As I see it, when someone says “I want Markdown support,” they can mean three different things. Some users would be happy with one or two of these, while many are going to want all three:
-
Importing of Markdown text into OO, which will likely call for some configuration options, much as discussed above regarding iThoughts.
-
Parsing of Markdown tags typed into OO. I haven’t considered this deeply, but perhaps it could be handled with a new “Markdown” column type, which is essentially how Outlinely handles it. A Markdown column could behave much as a Rich Text column, but adding support for **bold** and _italic_ tags. (And, in my opinion, bonus points if the tag characters are hidden, except when the node is being edited.)
-
Exporting of OO outlines to Markdown files, regardless of column types. Again, I imagine this would call for some configuration options.
I don’t think I’ve likely said anything particularly new here, but wanted to keep the conversation alive, perhaps provide some clarity to people at Omni Group, and give other Markdown users something with which to agree or disagree ;)
3 Likes
I exported OPML from OmniOutliner and then successfully used Scott Lowe’s opml2mmd script to convert it into markdown using:
opml2mmd xyz.opml xyz.md
This file then copy/pasted beautifully into hackmd.io :)
1 Like
Stumbled across this thread, and figured I would add that MultiMarkdown does have an official MMD<->OPML “spec.”
In 2005 I wrote a plugin for OmniOutliner to export as Markdown/MultiMarkdown. The same conventions were further refined in MultiMarkdown version 6, which has built-in read/write support for OPML (as well as iThoughts’ ITMZ format). This newer spec allows safe “round-tripping” between plain text and OPML without losing information, assuming a “valid” document. I wanted OPML to become a “first class” document format for MMD, and this required a couple of “tricks”.
(NOTE: MultiMarkdown-6 supports OPML but does not currently support the native OmniOutliner file format directly. Assuming that format is still similar to the XML format it used to be, that would not be difficult to add. For my needs, the OPML format was more flexible, and allows support for users of Linux and Windows machines.)
An important requirement for this effort was to be able to take any plain text MultiMarkdown file, convert it to OPML, convert that OPML back to plain text, and end up with an identical file to what one started with.
The primary goal for this was to be able to simultaneously work on a single document in MultiMarkdown Composer (for text editing) and an outliner or mind mapping tool (for visualizing the structure of the document and being able to rearrange it quickly and easily). When writing more complex documents, it’s trivial for me to have the editor and mind-mapping windows side by side and see changes reflected immediately in both windows. A trivial example of this is shown here.
-
Markdown headings (
# Foo #) become levels in the outline. Older versions would strip “incorrect” levels (e.g.### barfollowing# foo), but the newer version effectively corrects it to## bar. (This is one instance where data would be lost, if that### barwas important for some reason.) (NOTE: The MMD metadatabase header levelallows you to modify the#'s to<h>'s conversion. For example, setting it to 2 would mean that#means<h2>and##becomes<h3>. This allows you to maintain the desired HTML while still having a valid outline structure that starts with a first level outline item.) -
Metadata is stored as a trailing metadata node at the end of the outline. The metadata itself is stored in the note attribute.
-
Any text between headings is stored as the note for the preceding header. This includes whitespace, which allows preservation of your desired whitespace conventions (e.g. I like to have two blank lines after content and before the next heading, but others may prefer something different.)
-
If there is content before the first heading in a document, this is stored as “Preamble” node, and the content is stored in the note attribute.
-
No attempt is made to differentiate between Setext and ATX headers. Everything will end up as ATX when converting OPML back into plain text
To be clear – this is the official MultiMarkdown approach to converting MMD <-> OPML, but it doesn’t mean that others have to build compatible tools.
4 Likes
Given that OO is a rich text outliner, preservation of in-line emphases and links seems likely to be a typical requirement.
The columnar character of the outliner also seems likely to translate into some level of interest in FoldingText / Taskpaper style @key(value) tags.
