Starting in early 2016 I have been working on and off on a toolkit (available on Github) to support me in creating and maintaining a large set of illustrations I created in OmniGraffle for Sociocracy 3.0.
However, almost three years later, I find that did not work out too well, and due to a number of technical challenges I encountered, I now need to figure out where to go from here.
So I decided to explain my problem in some detail here, including a bit of background of the project I’m using this for, what I discovered when automating OmniGraffle, and some strategies I already considered.
I’m curious for any ideas or recommendations, and especially for corrections of my many misconceptions and unfounded assumptions.
Also, maybe there is somebody out there who benefits from my experiences and research. Please contact me if you think I might be able to help you out.
And just so that you know what to expect: At roughly 5000 words, this will be a 15-20 minute read, more if you start clicking on links. All my code I am talking about in this post is available on Github.
What am I trying to achieve?
First a bit of context: I am co-author of Sociocracy 3.0 (a.k.a “S3”), a conceptual framework and a practical guide for more conscious and effective collaboration on organizations.
We release everything about S3 under CC BY SA, because we want to make it as simple as possible for people to use and remix what we provide in all sorts of ways they may find valuable. The main resource is a handbook that can be published in various formats through an open source toolkit I built on top of other free and/or open source software, but there’s a few other resources we create, too.
Adoption of S3 was slow at first, but now it’s picking up pace, and an increasing number of people want to contribute to translating resources into their own language to make them accessible to their peers and coworkers. As an open source project, we can use the translation platform Crowdin for free, and we currently have a German, a French and a Hebrew translation already online. Translations are done by the community, and thanks to automation, we can publish a new version in minutes. That’s how it should be in the 21st century, and I know that without a professional translation platform the quality of the result would be significantly lower. Thanks, Crowdin, you’re making a huge difference for us!
The case for automation
However, at the moment, all the translation magic only works for text, and not for the 130 illustrations I have created in OmniGraffle for the project.
Maintaining those illustrations in one language is a challenge in itself, because whenever we learn something new about teaching S3, we want to update our resources so that people can benefit from what we learned. That means that, as we are updating the text, there is also a lot of updates to individual illustrations, and continuous refactoring of the entire body of illustrations to maintain coherence.
Translating illustrations is still a technical nightmare these days, because there is little tool support and a lack of open standards and formats, and of course it becomes even harder when there is a steady stream of new versions of those illustrations. The volunteers, who do all the translations in their spare time, should not be bothered with menial technical tasks like copying and pasting text out of the translation platform into a proprietary Mac App. Most of them don’t even own a Mac.
Still, I believe with good software, after some transition period where I learn how illustrations need to be laid out to support multiple languages, we should be able to achieve almost full automation for building translated illustrations.
At the moment, I maintain the German translations of those illustration myself, and that is, frankly, a major pain in the ass, and a process that will not scale for any language I do not speak myself. It’s also definitely not how I think things should be in the 21st century. Now that there’s a Russian and a Dutch version coming up, I really need to get my act together and figure out how to automate this properly.
Automating OmniGraffle with Python
When I first started looking into automation, I was looking for a solution for exporting a growing number of illustrations whenever we had to build a new version of our English handbook (which was, at that time, little more like an extended slide deck created with Markdown and Deckset and a few small Python scripts).
I quickly I decided that AppleScript was not the way forward for me, mainly because I failed to see how I could use version control and automated tests with Script Editor and Automator, and the fact that the official documentation did not talk about either raised some red lights for me. (Note: I now know that this is possible, but you have to jump through a few hoops)
Then I discovered a Github project for exporting OmniGraffle documents that used Python, so I forked that and built some code on top of it until I ended up with a fairly comprehensive toolkit that could do the following:
- export any number documents to various formats with various settings (while preserving the current export settings in OmniGraffle)
- replace colors and fonts in OmniGraffle documents
- run any other code on any object inside the document (because it had a simple plugin API)
Development was mostly triggered from changes I needed to make to my illustrations, e.g. when I found that I needed to update the illustrations to use a new font and a consistent color palette, I started writing some code for that.
And when we decided to translate our handbook into other languages, I started looking into ways supporting that with software as well.
We ended up using Crowdin as a translation platform for the S3 handbook, because that’s free for OpenSource projects. I fully automated the build process, and I intended to do the same for extracting texts and injecting translations into OmniGraffle documents. Can’t be too hard, I thought. But I discovered more and more problems.
While exporting files had been pretty straightforward, interacting with objects in the document was not so simple. At first I thought this was just because documentation was limited to the dictionary that is visible in Script Editor, and the technology to connect Python to Omnigraffle - py-appscript - had been unmaintained for a couple of years.
Here’s a couple of the problems I found (and reported to OmniGroup support):
- Read access to some elements inside a document is broken, most notably for everything inside shared layers, but also for some (but not all) groups, subgraphs, tables and solids
- Writing properties (e.g changing text) and then saving the file often results in OmniGraffle not saving those changes. I must say this was a really surreal experience: I watched OmniGraffle replace the text with a translation on my screen, and afterwards the saved file still contained the original text afterwards. I found a workaround: when adding some User Data to the object where I updated text, the object saved just fine.
- Some values were not exposed by OmniGraffle, e.g. the opacity, which I relied on in my illustrations
Support acknowledged those issues, but for all I know they were never fixed, at least they never told me that it was.
Then there was a new version of OmniGraffle (7.8?) with change in export API that broke my code, so that I decided to stick with the older version until I could find some time to figure out how to move forward.
I had some workarounds in place, disabling shared layers before extracting and inserting, and a lot of manual steps, so for a while, I was able to live with the situation.
Automating OmniGraffle with JXA
Things changed when 2 months ago I finally decided get a new SSD for my Macbook and go for a new installation of High Sierra, because after that I somehow was unable to get py-appscript to work on my machine. After a bit of fruitless tinkering and researching, I decided to dive into JXA, because I thought this might be a more sustainable approach. My JavaScript was a little rusty, but I thought with today’s toolchain (and all the code available through npm) it should be pretty straightforward to port my Python code to JXA. I discovered the JXA Cookbook, which helped me get started, and for my first tests I created a Service with automator for exporting OmniGraffle documents.
As my code got a bit more complex, I settled for running JavaScript through osascript in the terminal, because that way I am able to use Sublime Text with ESlint, and the Safari debugger. With that approach, however, it’s impossible to split code into several files without sacrificing line numbers when an error is thrown. I learned that node-jxa might be a way forward here, and I will definitely try that should I decide to stick with JXA.
The current state of my experiments with JXA and Omnigraffle is available on Github.
Here’s a list of the problems I found with JXA
- Export is broken, the exported files do not contain all visible objects (it’s possible that this bug only affects objects in shared layers, but I’m not sure)
- Some objects in the document can’t be accessed through JXA, again it’s all items in shared layers, but also some groups, tables and subgraphs
- Sandboxing sometimes gets in the way of scripting, because OmniGraffle is not allowed to access documents. So I needs to manually open all files before running a script, which is really annoying.
I raised these issues with OmniGroup support, and I hope they will be fixed soon. That won’t fix the fundamental flaws in JXA, but might make for a workable solution if node-jxa works ok.
What about OmniJS?
Apparently there’s two different JavaScript APIs available for OmniGraffle: the API Reference (available inside OmniGraffle) has groups represented as simply another Graphic in a Layer’s Graphics collection, and the OmniGraffle dictionary (available in Script Editor) lists groups as a separate collection within a layer. From now on, I will refer to what is described in the API reference inside OmniGraffle as OmniJS.
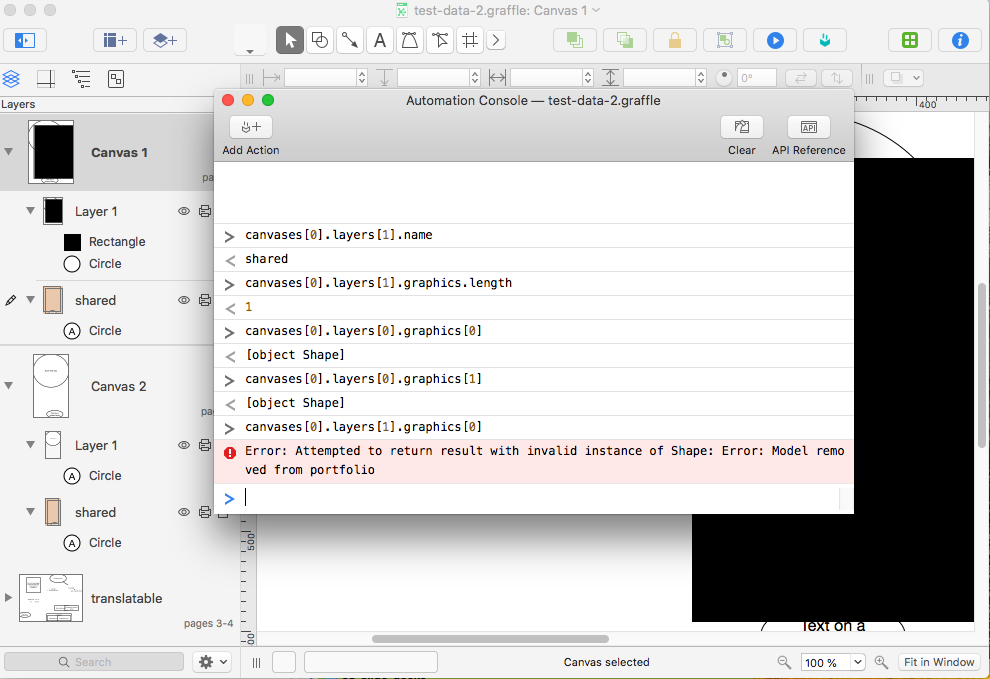
Even with OmniJS, the problems with shared layers are still present, you can see for yourself by opening this test document, and then the console (in v7.10.2):
> canvases[0].layers[0].name
> Layer 1
> canvases[0].layers[1].name
> shared
> canvases[0].layers[0].graphics.length
> 2
> canvases[0].layers[1].graphics.length
> 2
> canvases[0].layers[0].graphics[1]
> [object Shape]
> canvases[0].layers[1].graphics[1]
> undefined
> canvases[0].layers[1].graphics[0]
> Error: Attempted to return result with invalid instance of Shape: Error: Model removed from portfolio
(Note: It’s a pity the console does not allow for copy and paste of several statements and the corresponding output.)
Edit: revisiting this problem showed that the bug is a bit more complex to trigger, and I appear to have missed a line in my original post when I copied them individually for the console into this post)
Fun fact: When I attempt to copy any object in a shared layer as JavaScript through the context menu, the resulting JS code for those objects is incomplete, because obviously even OmniGraffle cannot access them.
Also, when I get some text that is formatted, this formatting is lost.
> canvases[2].layers[1.graphics[3].text
> Box with some bold and some italic text.
> And a second paragraph
This last bit alone means that I will not be able to automate translations through OmniJS. Rich Text exposed as attribute runs in the other document model may be a pain to process in JavaScript, but as long as I’d stick to very basic formatting, it’s possible to convert that into Markdown (or similar) and back. The new text property, however, just acts as if the formatting isn’t there. Or maybe am I missing anything obvious here?
I also had a closer look at omni-automation.com, which appears to be the most comprehensive documentation apart from the API Reference itself, and I downloaded the example plugin. I learned a lot, and left with a few unanswered questions:
- Can I use the safari debugger for debugging plugins? Would that work with code in libraries also?
- Would I need to open/close omnigraffle whenever I change code in a plugin, or would it autodetect new or changed actions ?
- For my toolkit to process a number of OmniGraffle documents, it appears I would require a plugin, and trigger actions inside the plugin through Script Links (from a command line script or through a service), is that correct?
- What is the best setup for developing and testing plugins? I can imagine a symlink inside the OmniGraffle plugins folder that points to a working copy, I could also clone the repo directly to the plugins folder (which would impose a certain structure on the repo), or I could “publish” to the plugins folder (e.g. with a makefile) whenever I change some code.
- is there a specific coding style encouraged for plugins (the example code is a bit inconclusive here)?
Personally, I find the setup costs for writing an OmniGraffle plugin is rather high, but maybe that’s typical for plugins developed in JavaScript? Here is an example where you can create a plugin with a mere 4 lines of code in a single file, and here is another one where a plugin needs only a single line of boilerplate code.
Where to go from here?
On top of the Hebrew and French translations, which are in dire need of illustrations in each language, there’s also Russian, Spanish and Dutch translations projects on their way now. So I need to come up with a solution soon.
I found four general approaches, which are not necessarily mutually exclusive:
- Forget about extracting from and inserting texts into OmniGraffle, and support manual translation of assets as good as I can.
- Wait until the bugs in OmniGraffle are fixed, and deal with the technical idiosyncrasies of automation through JXA.
- Translate OmniGraffle source files.
- Move my illustrations out of OmniGraffle to another platform.
Maybe there’s even something else I haven’t yet thought about?
Let’s look at each one in a bit more detail:
Strategy 1: No automation
No automation basically means translations have to be manually inserted into standard image files (PNG or SVG), because I cannot expect volunteers to own an OmniGraffle license, let alone a Mac. There’s many free SVG editors and image editors for any platform, some are even browser-based, so the barrier of entry might be quite low.
Crowdin provides some support for translating assets , they can be included in the proofreading workflow, but will not benefit from auto-translation and frictionless collaboration between multiple translators. There’s a two things I could do to patch this up and assist translators:
- OmniJS’s ability to export plain text might be used to put source texts into crowdin, so that translations benefitting from all features of the translation platform can then be copied and pasted into the image editor and formatted manually.
- Automatically create and upload image-diffs to Crowdin, so that translators can see the actual changes to an illustration and decide whether or not this warrants a new version.
But all that still feels like sticking a band-aid to an amputation.
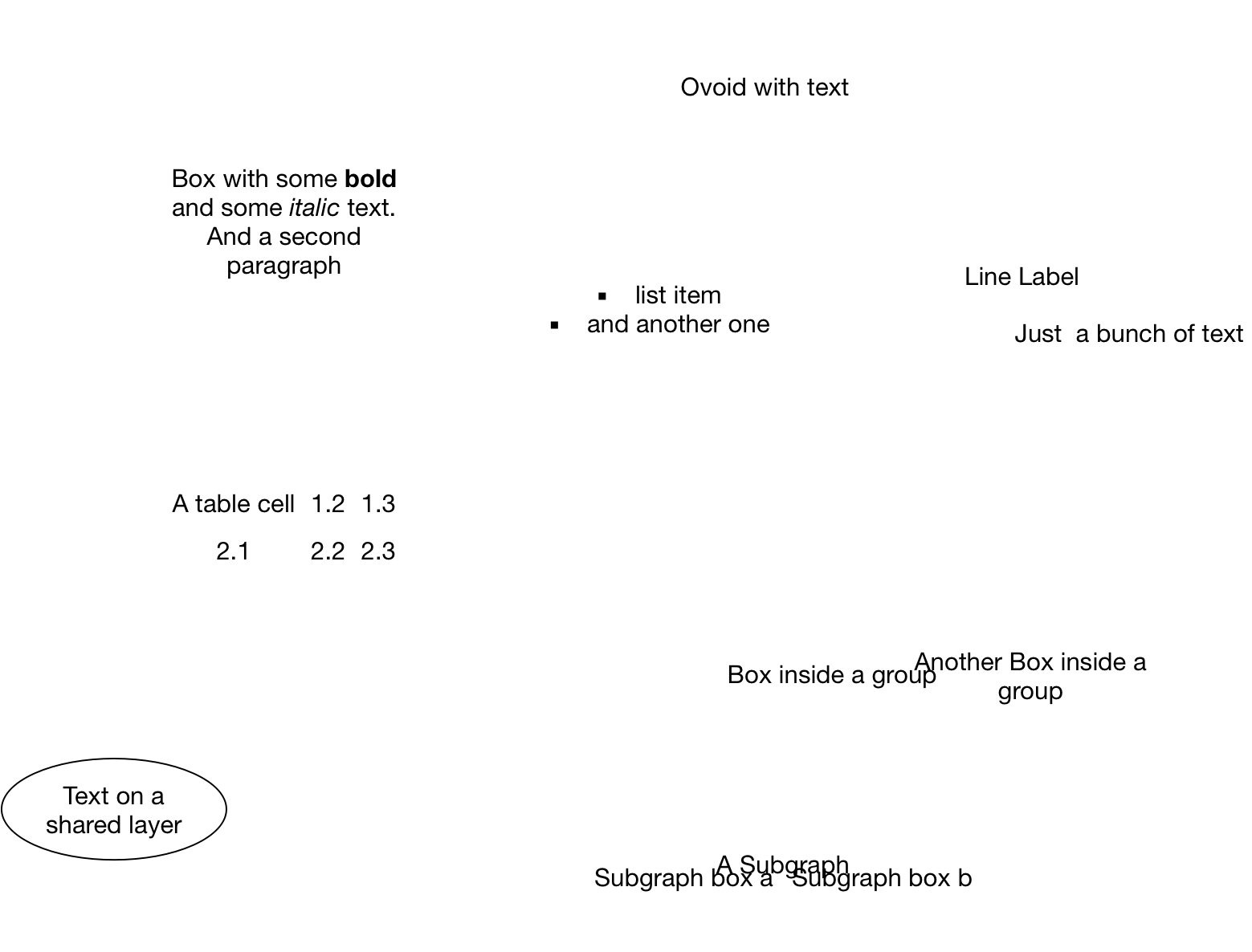
For SVG files, it first appeared that I would merely need to figure out how to integrate them in to my publishing workflow, and everything else should be a piece of cake. A closer look revealed that while text in SVG exported from Omnigraffle is visually quite similar to the source, the structure of the text is structure is broken up so badly it will be a nightmare to edit in Inkscape.
Consider this bit of Rich Text in the OmniGraffle document:
<string>{\rtf1\ansi\ansicpg1252\cocoartf1561\cocoasubrtf600
{\fonttbl\f0\fnil\fcharset0 HelveticaNeue;}
{\colortbl;\red255\green255\blue255;}
{\*\expandedcolortbl;;}
\pard\tx560\tx1120\tx1680\tx2240\tx2800\tx3360\tx3920\tx4480\tx5040\tx5600\tx6160\tx6720\pardirnatural\qc\partightenfactor0
\f0\fs32 \cf0 Box with some
\b bold
\b0 and some
\i italic
\i0 text.\
And a second paragraph}</string>
This is what it looks like when exported to SVG:
<text transform="translate(346 188.59595)" fill="black">
<tspan font-family="Helvetica Neue" font-size="16" font-weight="400" fill="black" x="7.864" y="16">Box with some </tspan>
<tspan font-family="Helvetica Neue" font-size="16" font-weight="700" fill="black" y="16">bold</tspan>
<tspan font-family="Helvetica Neue" font-size="16" font-weight="400" fill="black" y="16"> </tspan>
<tspan font-family="Helvetica Neue" font-size="16" font-weight="400" fill="black" x="8.128" y="34.46411">and some </tspan>
<tspan font-family="Helvetica Neue" font-size="16" font-style="italic" font-weight="400" fill="black" y="34.46411">italic</tspan>
<tspan font-family="Helvetica Neue" font-size="16" font-weight="400" fill="black" y="34.46411"> text.</tspan>
<tspan font-family="Helvetica Neue" font-size="16" font-weight="400" fill="black" x="30.504" y="52.91211">And a second </tspan>
<tspan font-family="Helvetica Neue" font-size="16" font-weight="400" fill="black" x="43.256" y="71.36011">paragraph</tspan>
</text>
It’s obvious that with the absolute positioning of parts of a sentence, all attempts at translation are inevitably bound to fail, because they will end up all over the place when translated strings have a different length.
PNG files are a much bigger hassle initially, because I would need to provide translators with raw files without any text. This requires a massive refactoring of all illustrations and results in my OmniGraffle documents becoming unnecessarily complicated, moving all text out of shapes and into separate layers. Obviously that’s bad for future maintenance. It’s a pity that artboards can’t help here, because they can only export what is above them, and text is obviously above everything else. Also I would have to resort to tedious manual export with all text layers disabled, but until the export bug is fixed in OmniGraffle, that’s the only way. Once that bug is gone, a simple script could disable those layers and export everything.
But with either format, SVG and PNG, this strategy would insert a massive amount of friction into the entire translation process: the burden of maintaining quality is put entirely on the shoulders of translators, and even small updates might come with an unreasonable amount of additional work. I am concerned this might result in outdated illustrations in target languages, a sacrifice of visual quality, and definitely a significant workload dumped on top of volunteers.
But at least it’s something to try if all else fails. Translators will not like it, so maybe they would just translate what they consider important. Still, better than nothing.
However, I have a couple of OmniGraffle files with a lot more text here and here, that also need translating, but would not at all work with this approach.
Strategy 2: Stick with OmniGraffle automation
A reported all the bugs I know to the OmniGroup, and I’m sure they will eventually resolve them, however they still have their own list of priorities which need not be aligned with mine.
But even if those bugs are fixed, OmniJS would still not provide an API to extract and insert formatted text, so I assume I am still stuck with JXA, a technology Apple might kill off rather sooner than later.
Anyway, once I can get my hands on a version of OmniGraffle that fixes the bugs I reported, it probably makes sense to look into node-jxa and see if that is a way forward for me, because that would allow for standing on the shoulder of giants when it comes to existing packages and development tools. OmniJS has, at least as far as I understand it, significantly a longer way to go here.
Strategy 3: Translate Omnigraffle Source files
Three years ago, one of the first things I tried with Crowdin was uploading the OmniGraffle XML (plist) documents. Since the text inside the XML being stored as stored as Rich Text, it was not possible to extract translatable strings through the XML tools provided by Crowdin. This is why I looked at ways to extract text via the scripting bridge.
However, I guess it’s not too hard to write some code that extracts RTF from those XML files and converts it to Markdown, or any other suitable format that Crowdin understands.
There’s all kinds of potential technical pitfalls involved, but at least I’m mostly independent from the development of OmniGraffle (apart from revisions to the file format itself), and I’m free to use the full scale of tools, languages and libraries available. And I probably can start with processing only a subset of rich text. Of course, my habit of consistently using Open Sans Light for normal text and Open Sans Regular for bold text complicates things a bit, but that is not a big issue.
So that strategy actually sounds pretty promising right now.
Strategy 4: Abandoning OmniGraffle
Fully aware that the moment I migrate my illustrations out of OmniGraffle I will lose any meta information that does not have a visual representation, e.g. artboards, stencils, actions, multiple canvases in one document, shared layers, and the minimum of semantic markup for text that is present in Rich Text but not exported to SVG.
Of course, what now serves as a deterrent to leaving the platform would also become a significant barrier to returning at a later date, e.g. once all the bugs are fixed, and automation might again become a more viable option.
In my experiments with exporting SVG explained above I also tried importing the very same SVG file back into Omnigraffle. Here’s the result:
<string>{\rtf1\ansi\ansicpg1252\cocoartf1561\cocoasubrtf600
{\fonttbl\f0\fnil\fcharset0 HelveticaNeue;}
{\colortbl;\red255\green255\blue255;\red0\green0\blue0;}
{\*\expandedcolortbl;;\csgray\c0;}
\pard\tx560\tx1120\tx1680\tx2240\tx2800\tx3360\tx3920\tx4480\tx5040\tx5600\tx6160\tx6720\pardirnatural\qc\partightenfactor0
\f0\fs32 \cf2 Box with some bold\
and some italic text.\
And a second \
paragraph}</string>
The formatting of the text is simply lost. Other things are lost too, and the result looks quite different from the original. The same is true for Visio, where the result is arguably even worse. It appears once I’m out of OmniGraffle, there is probably no way back without redrawing everything.
However, the important question for me right now is: Will it help my project if I abandon OmniGraffle, and if so, where could I turn to?
There’s two directions I could take:
- manually re-creating all my illustrations in a language for vector graphics (or similar)
- using another editor with better support for translations, hopefully re-using at least some bits of my illustrations
Lets look at each in a idea more detail.
Languages for vector graphics
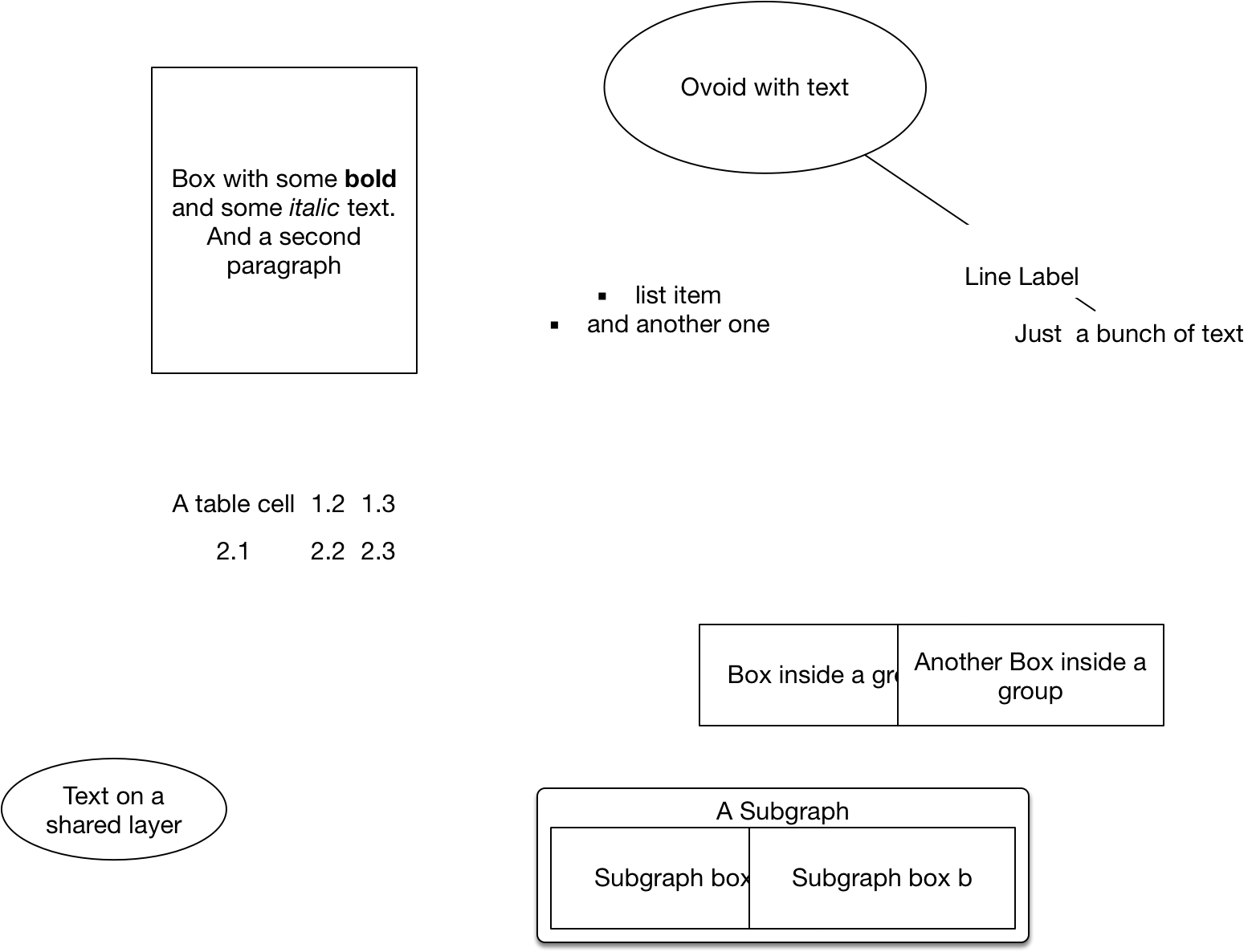
The illustrations for the handbook are mostly not very complicated (with the exception of some illustrations for structural patterns), and based on just a few recurring patterns. The visual style is also pretty basic, so I assume there’s a wide range of tools suitable for recreating my illustrations.
And maybe in the process I could address two things I really miss in OmniGraffle:
- A simple way to reuse design elements and visual appearance so that whenever I change a recurring design element, it changes in all the documents it’s used. That would make refactoring illustrations so much simpler.
- A text-based format that lends itself for meaningful diffs for each update. This implies, among other things, separation of content from visual representation.
There’s a couple of interesting approaches, most of which are collected in this blogpostand this thread on reddit. I haven’t looked too deep into this so I can only paint with a really broad brush here:
First there’s tools for Tex, mostly Pstricks, Asymptote, and TikZ/PGF . They achieve decent separation of content and style, I can imagine that a template engine or Gettext might be used for extracting and/or substituting translations. The examples available on the web look promising, although the learning curve of any of the three appears to be rather steep for somebody with only a modicum of experience with Tex. That definitely includes me (even though rendering of the PDF version of our handbook is based on Tex), and also most people who would want to use and adapt the source files of my illustrations. I might still export them to SVG, though. I would need to do some more research into this, but for now this looks like a lot of work.
Then there’s a few other languages, which — at least from what I gathered — are intended for visualization of either datasets or mathematical functions, or they lacking features and/or a significant user base. However, I’m curious for any hint that makes me re-evaluate this assumption.
Last, there’s a bunch of libraries for programming languages, e.g. for Python or Javascript, which are more accessible for me than a Tex-based solution, but again, I need more research to figure out which are the most viable options.
I think with this last approach there might even be a way to convert the output of OmniGraffle’s “Copy as JavaScript” to get me started.
Whichever technology I’d chose, I estimate a full migration of all illustrations will take me at least month.
Other editors
From my limited understanding of vector graphics formats, SVG is the most widely supported open format out there, so that’s the first thing to look at.
From what I understand it might be necessary to stick with one specific editor, because there’s different versions of SVG and certain idioms or structures one editor uses that might not survive a round trip.
Inkscape
There’s a variety of editors available, and the most comprehensive editor working with SVG as a native format is probably Inkscape. (Note that Adobe Illustrator does not write standard SVG, but embeds its proprietary AI format within the SVG files). Inkscape can be automated with Python and Ruby, which I both prefer to JavaScrip.
I’m not too happy with the Mac version of Inkscape, even though I can see a certain benefit of working with an open source app that is accessible to anyone who wants to reuse and translate my illustrations.
Since there’s obviously a bit of a learning curve, I estimate a migration of all my illustrations to Inkskape/SVG will take at least 3-4 weeks, most likely longer.
So what’s the benefit?
My first tests with Inkscape revealed that the simple example text I used above it will be directly translatable through Crowdin’s XML support. However, I don’t expect this to hold up in real life, i.e. for longer text with more formatting.
I researched a few other approaches for translating SVG files, e.g. adding HTML to SVG as foreign object, inserting translations through a template engine or using XSLT to create XLIFF from SVG, but I’m afraid each of those has only a very limited use cases, and/or is not directly supported by SVG editors. So I’m afraid, after all I wouldn’t gain much for my significant investment that makes this strategy worthwhile.
Sketch
Another avenue of further research might be Sketch, which is at least on par with OmniGraffle when it comes to usability, and has a few interesting ideas that would make my life much easier, like symbols, text styles and libraries. Sketch is extensible through JavaScript plugins and fully embraces npm, no wonder there’s already an active developer community providing 634 (!) plugins with really interesting ideas, e.g. Sketch Runner. Among those are at least seven plugins for translating Sketch files (1, 2, 3, 4, 5, 6 and 7). The fact that there’s a large community of people who already have given this matter a some thought is encouraging, even though I’d need to research a bit more to see where this might be going.
Migration of my illustrations would happen through SVG, and I’d probably take around 2-3 weeks to polish everything, because I could employ symbols, libraries and text styles to speed up the process. But maybe I’m overly optimistic, and this time I’d look closely before I leap. Especially because Sketch is again a proprietary platform on Mac, so reuse of my illustrations will still be limited.
What now?
With translation projects for at least four languages lacking access to illustrations, I need to come up with a solution rather sooner than later.
Maybe the way forward lies in putting several of those pieces together?
So I’m curious for any thoughts or wild ideas even remotely related to this challenge.



{kind=link}